















A Note from Dalia
As engineering leaders, we’ve all felt the fatigue of reactive maintenance: endless alerts, repetitive debugging, and teams that are busy but not truly moving forward. I wrote this playbook to help leaders break through that wall.
Drawing on my experience scaling engineering organizations and integrating AI into daily workflows, I will share with you how agentic AI workflows, powered by mobile app observability, can transform maintenance from a drain into a solved problem.
This is not about chasing velocity. It’s about designing leverage, freeing teams to build boldly while sustaining morale and delivering measurable business impact.
The AI ROI Paradox: Mobile Engineering at Machine Speed, Value at Human Pace
Enterprises are investing heavily in AI coding assistants. Code is produced faster than ever, yet business outcomes remain stubbornly flat: sprint velocity stalls, release cycles drag, and customer satisfaction is stagnant.
The result is productivity theater. Developers report feeling faster with AI tools, yet organizational metrics remain unchanged. This illusion of progress is reinforced by loud productivity: a flurry of visible signals such as pull requests, lines of code, and green builds that mask the absence of real customer value.
Agentic workflows redefine that model by governing how work moves from detection to prevention. Mobile app observability provides the signals and context that make these workflows effective. Together, they shorten the distance between code and customer experience, allowing teams to spend less time maintaining systems and more time building products that matter.
This blueprint is organized around the agentic loop: detect → triage → resolve → prevent, with each chapter showing how leaders can move beyond monitoring to autonomy, and beyond fixing to building.
.png)
Chapter 1 | The New Reality of Mobile Engineering and Mobile App Performance Metrics
Mobile apps are no longer supporting features; they are the business. In 2025, users spent 4.2 trillion hours in apps globally, with smartphones averaging 4.8 hours of use per day.
The stakes are unambiguous. Mobile app performance metrics have become leading indicators of revenue, retention, and brand reputation. Luciq’s 2026 No Margin for Error report reinforces this collapse of tolerance: 15.4% of users uninstall after a single crash, and over half leave after just 2 - 3 crashes. During peak sales, 53.2% abandon purchases when apps slow down or fail.


The reputational impact is equally stark: 77.5% of users say repeated poor performance damages brand perception, and 30% are very likely to permanently switch to a competitor after failures. The margin for error has effectively disappeared.


For mobile engineering leaders, this pressure is intensified by the nature of mobile development. Unlike web environments, mobile releases must pass through app store approvals. A defect in production cannot be rolled back instantly and may persist until the next review cycle. Reliability is no longer a technical concern alone, it is a direct business risk.
To compete in this environment, leaders must design workflows that collapse the distance between code and customer experience.
The “So What?” for Leaders
Chapter 2 | Mobile App Observability: The Hidden Costs of Today’s Workflows
Here is an uncomfortable truth: developers often feel dramatically more productive with AI tools, while organizational outcomes tell a different story. This is the Perception Gap.
The Stack Overflow Developer Survey 2025 found that 84% of respondents are using or planning to use AI tools in their development process, yet nearly half worry about accuracy. METR’s 2025 confirmed the risk: experienced developers expected a 24% speedup with AI but actually took 19% longer to complete tasks.
This gap becomes visible when we compare vanity metrics with value metrics:
More output means little if value is not delivered to the user. Each pod is a self‑contained unit consisting of 4 - 6 engineers, a Product Manager, a UX Designer, and a Product Marketing Partner. Productivity theater is the systemic illusion it produces, where organizations mistake this noise for progress.
Atlassian’s State of Developer Experience Report 2025 reinforces this reality: 50% of developers lose more than ten hours per week to inefficiencies, and 90% lose at least six.
Developers don’t just lose time to inefficiencies; they lose their ability to stay in flow. Jellyfish reports show that context switches, jumping from frontend to database to infrastructure, can take 30–60 minutes to fully recover productivity (even short interruptions average 23 minutes before focus is regained). When cognitive load is exceeded, delays, errors, and burnout follow.
This isn’t just a workflow annoyance; it’s an architectural failure. Agentic Observability is a Flow State Preservation strategy, eliminating the gap between a developer’s intent and the machine’s execution.
The Maintenance Tax
But the cost of broken workflows isn’t borne by developers alone, it compounds across the organization. When observability tools alert teams to problems but do not help solve them, enterprises pay a maintenance tax on every engineering dollar.
- Cost of Inefficiency: If 30% of engineering capacity is spent on reactive rework, senior engineers are effectively paid to perform dashboard archaeology instead of building features.
- Opportunity Cost: The true loss is not just salary; it is the feature that did not ship, the competitor that reached the market first, and the modernization effort deferred yet again.
This is why triage, not detection alone, becomes the inflection point. Without intelligent clustering and ownership routing, better detection only creates more noise.
Chapter 3 | From Mobile App Observability to Agentic AI Workflows
Mobile app observability was a critical step forward. On its own, however, it is incomplete.
To understand why, we must distinguish between generative AI and agentic AI. Generative AI describes and suggests. Agentic AI acts.
Agentic systems detect issues, diagnose root causes, initiate resolution, and prevent recurrence using context. This mirrors evolutions already underway in other domains: self-driving cars, self-healing infrastructure, and now, self-healing applications.
Building effective agents requires more than automation. It requires context: data that defines how the application should behave across users, devices, OS versions, and feature states. By collecting and organizing this information, leaders enable AI agents to reason about problems the way experienced engineers do.
As a result, the developer’s role shifts. Engineers' time can be leveraged as builders versus constantly fixing complex systems.
Chapter 4 | The Unsexy Truth: Engineering Guardrails for Agentic AI Workflows
The promise of agentic AI is speed. Without guardrails, however, that speed simply compounds technical debt. Before scaling AI adoption, engineering leaders must strengthen the fundamentals.
- Strengthen Testing Guardrails: AI will generate more code than teams have ever produced. Without robust automated validation frameworks, organizations accelerate regressions instead of delivery.
- Solve the Context Problem: AI tools lack historical and architectural awareness. Qodo’s 2025 research shows that 44% of developers who report degraded code quality attribute it to missing context.
- Address the Review Bottleneck: When code is generated quickly and in large volumes, the role of the human reviewer becomes more important, not less. The core purpose of a code review, holding the implementation up against the problem and asking “is this the simplest way to solve this?” It hasn’t changed. What has changed is that there’s now more code arriving faster.
- Converge on Tools: Tool sprawl fragments knowledge and accountability. Productivity gains come not from constantly switching tools, but from standardizing and mastering a cohesive stack.
Guardrail Maturity Checklist
Rate your organization 1–5 on each guardrail to identify where to invest first:
On Tests and Observability
Tests validate assumptions: does the code behave as the developer intended? Observability reveals reality: what is the code actually doing in the hands of real users? In a world where AI generates more code, faster, the gap between what was tested and what actually happens in production is growing.
This gap is especially severe on mobile, where thousands of device models, OS versions, network conditions, and battery states combine in ways no test matrix can fully capture. A mobile-dedicated observability solution closes that gap by providing real insight into app performance after release.
Tests give you confidence before you ship. Observability gives you clarity after you do. Increasingly, that clarity is where the real value lives.
Chapter 5 | Mobile App Observability and the Agentic Loop
Guardrails prevent chaos. Autonomy eliminates it.
Traditional observability tools surface problems but stop short of fixing them. In an era where AI accelerates output, the bottleneck is no longer writing code, it is sustaining reliability at scale.
The Agentic Loop formalizes this shift. In the Agentic Loop, each stage of the maintenance lifecycle is powered by autonomous agents.
- Detection: High-fidelity signals beyond crashes, including UI performance, session replay, and automated instrumentation.
- Triage: Intelligent clustering and ownership routing that eliminate alert fatigue.
- Resolution: Root-cause analysis delivered directly into the developer environment, minimizing context switching.
- Prevention: Real-time monitoring and policy-based rollbacks that stop faulty code before it scales.
Agentic AI Workflows in Action: The “Checkout Crash”
Chapter 6 | Engineering Leadership in the Agentic Era
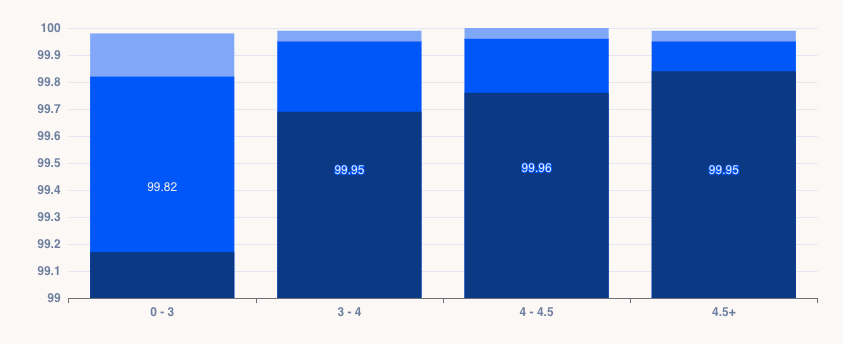
Luciq’s 2026 Mobile App Performance Playbook shows that sustaining 99.95% crash‑free sessions is the threshold for 4.5+ ratings, while even a 0.1% dip translates into tens of thousands of failed sessions.
In the agentic era, leadership is no longer about managing velocity; it is about architecting leverage. According to the LeadDev Engineering Performance Report 2025, 65% of leaders are now prioritizing outcomes over raw output.
To lead this shift, we must replace "speed" with three high-leverage metrics:
- End-to-End Delivery Time: The total duration from the spark of an idea to customer-validated value. This is cycle time, a consistently solid measure of what bottlenecks hold the team back.
- Rework Rate: The percentage of effort lost to the “Maintenance Tax” versus iterating to deliver value to users.
- Customer-Validated Delivery Rate: The percentage of shipped work that produces a measurable change in a customer outcome metric: adoption, retention, task completion, NPS, or revenue. This directly highlights the effects of shipping features nobody uses.
Together: How fast do we go from idea to customer value? How much effort is wasted? And how much of what we ship actually matters?
Mapping the Path: The Seven Team Archetypes and Agentic Levers
The 2025 DORA report introduced Seven Team Archetypes that reveal how organizational health, team structure, and platform maturity shape performance outcomes.
Mapping archetypes gives leaders the diagnostic lens, it shows where teams are stuck and what constraints block performance. But diagnosis alone isn’t enough. To actually shift outcomes, organizations must redesign how teams are structured and how work flows. Archetypes explain the environment; pods operationalize the solution.
1. Structure: Organizing Around Product Surface Areas
Instead of dividing teams by technical silos (e.g., separate frontend, backend, and mobile teams), autonomous pods are organized around distinct product surface areas and customer jobs‑to‑be‑done.
- Anatomy of a Pod: Each pod is a self‑contained unit consisting of 4 - 6 engineers, a Product Manager, a UX Designer, and a Product Marketing Partner.
- Eliminating Dependencies: Because the pod contains all the necessary skills (frontend, backend, design, strategy) to take a feature from concept to completion, they eliminate external dependencies.
- The AI shift: This model is now mirrored in the “Builder” reference of engineers who ship products end-to-end. The unity of those skills produces the most value and we are starting to see this pattern emerge in the AI forward Engineering Organizations.
2. Enabling Autonomy in Pods
High‑leverage pods thrive when:
- Ownership is Automated: Clear boundaries ensure accountability. Issues are routed directly to the pod responsible for the code, eliminating bottlenecks.
- Flow State is Preserved: Engineers stay in their environment, pulling live production context directly into their development tools.
- Customer Empathy is Embedded: Rich replay data links UI actions, network events, and logs into a unified journey.
3. The Ritual of Business‑First Triage
Stop ranking bugs by technical severity alone; prioritize by revenue risk and customer impact.
- Old Way: “Fix this crash because it happens 1,000 times.”
- New Way: “Fix this hang because it affects the checkout flow for high‑value users.”
4. Concrete Outcomes
When pod structure is combined with autonomous workflows, the results are measurable:
- Higher Feature Adoption: Direct user insights validate features with design partners, driving adoption rates.
- Reduced Maintenance Load: Automated detection and diagnosis cut reactive maintenance work by 30 - 50%.
- Faster Decision‑Making: Small, cross‑functional pods equipped with real‑time data make decisions quickly.
Chapter 7 | The Zero‑Maintenance Mindset powered by Agentic AI Workflows
Every engineering team eventually hits “The Wall”: the moment when reactive maintenance consumes more energy than building new features. The answer is not the fantasy of flawless software, but the discipline of the Zero-Maintenance mindset: teams spend near-zero time firefighting because detection, triage, and resolution are automated.
The $1M Wall: Dabble’s High‑Stakes Proof Point
The Zero‑Maintenance mindset is already proving its value in high‑stakes environments.
- The Challenge: During peak events like the Melbourne Cup, a single outage could cost Dabble over $1 million in live placements. Engineers were spending 20 hours a week on reactive triage.
- The Action: They implemented agentic mobile observability to automate detection and triage.
- The Result and Business Impact: Resolution times dropped by 50 - 60%. Release cycles accelerated from monthly to bi‑weekly, protecting millions in revenue.
Chapter 8 | Building Boldly
The future of engineering is agentic. The only question is whether you will lead the shift, or be left fixing what’s already broken.
- For developers: Stay in flow and let autonomous workflows handle the noise.
- For leaders: Design organizations that harness autonomy without collapsing under it.
The call is clear: build boldly in the AI era of mobile, where observability meets autonomy.
Sources
- Sensor Tower. (2025). Global App Engagement Data.
- Luciq. (2026). No Margin for Error: What Mobile Users Expect and What Mobile Leaders Must Deliver in 2026
- Stack Overflow. (2025). Developer Survey.
- METR. (2025). AI Developer Productivity Study.
- Atlassian. (2025). State of Developer Experience Report.
- Jellyfish. (2025). Developer Productivity: Context Switching.
- Qodo. (2025). State of AI Code Quality.
- Luciq. (2026). The 2026 Mobile App Performance Playbook: A Leader’s Guide to Driving Growth
- LeadDev. (2025). Engineering Performance Report.
- DORA (DevOps Research and Assessment). (2025). State of DevOps Report.
- Luciq. (2026). How Dabble Protected $1M+ in Peak-Event Revenue.