














TL;DR: Mobile app crash prioritization ranks issues by their actual impact on user experience - frustration-free session rate, affected user count, and frequency - rather than raw alert volume. This means your team addresses the crashes driving the most churn and the worst reviews first, not the ones that are noisiest. Luciq's Agentic Mobile Observability platform automates this prioritization, surfaces the top-impact issues in a ranked list, and connects directly to your workflow tools so the fix process starts the moment the issue is identified.
Your frustration-free session score dropped two points overnight. The dashboard is red. There are fourteen open issues, three of which fired their alert threshold in the last hour, and your team's sprint planning is in forty-five minutes.
Which one do you fix first?
The honest answer, at most mobile teams, is: the one someone senior saw in Slack, or the one with the highest crash volume, or the one with the most user-facing surface area. The prioritization is not wrong, exactly. It is just not systematic. It is, in most cases, a judgment call made under time pressure by someone who does not have the full picture yet.
The problem is not that engineers are making bad decisions. It is that they are making decisions based on the wrong inputs. Alert volume is not the same as user impact. A crash that fires fifty times a day in a rarely-used flow costs less than a crash that fires ten times a day right before the checkout button. The first is louder. The second is more expensive. This is the mobile app crash prioritization problem in its rawest form.
Why Alert Fatigue Makes Mobile App Crash Prioritization Harder
Alert fatigue is a well-understood problem in software operations. Too many signals, too little signal-to-noise, engineers tuning out because the volume is not calibrated to importance.
In mobile specifically, it compounds. A typical scaled mobile app has multiple crash types, performance issues, ANRs, non-fatal errors, and UI hangs all arriving simultaneously. Some of them affect two percent of sessions. Some affect two percent of sessions but those sessions happen to be your checkout flow during peak traffic.
The traditional crash reporting approach puts all of these on a list, roughly ranked by frequency. The frequency ranking rewards crashes that are common. It does not reward identifying crashes that are revenue-critical.
According to the No Margin for Error report, 53% of users abandoned purchases during peak events due to performance failures, and 15.4% uninstall after a single crash. The crash that matters most to your business is not necessarily the one that happens most often. It is the one that happens at the worst moment in the worst place in the user journey.
What Impact-Based Mobile App Crash Prioritization Actually Looks Like
Impact-based crash prioritization uses a composite signal - frustration-free session rate, affected user count, crash location in the user journey, and frequency relative to session volume - to rank issues by their actual cost to the user experience and the business.
The practical effect is that your issue list re-orders. The crash affecting two percent of users on a rarely-visited settings screen drops. The crash affecting one percent of users at payment confirmation moves to the top, because that one percent represents a disproportionate share of transaction value and uninstall risk.
This is not a new idea. The challenge has always been implementation: building the scoring model, keeping it current, making it accessible in the triage workflow. The manual version of this requires a data analyst and a lot of tooling. The automated version requires the right observability platform.
Luciq: The Mobile App Crash Prioritization Dashboard
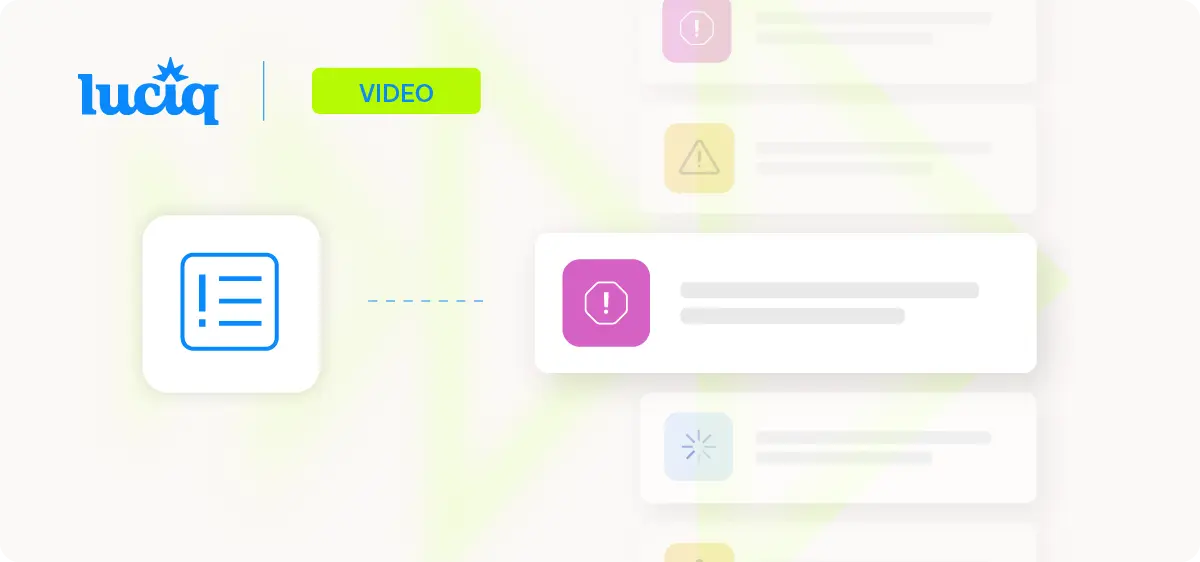
The video below shows how Luciq's automated prioritization works in practice. It runs under a minute. What it demonstrates is what impact-based triage looks like when it is built into the issue list, not assembled manually after the fact.
Here is what is happening at each stage:
The Starting Point: A Low Frustration-Free Session Score (0:00 - 0:14)
The video opens on a team with a declining frustration-free session score and a full dashboard of issues - crashes, performance problems, minor bugs - all arriving at once. The challenge is immediate: which one is responsible for the score drop, and which one should the team address first?
Without prioritization, this question gets answered by whoever has the most context in the room, which means the answer varies. With the Luciq issues list, it gets answered by the data.
How the Prioritization Works (0:14 - 0:27)
Issues in the Luciq list are ranked by their specific contribution to the frustration-free session score. Not by raw volume, not by how recently they were reported, but by how much they are actually degrading the user experience.
This means the issue at the top of the list is the one that, if resolved, would produce the largest improvement in the metric your leadership cares about. The engineering conversation shifts from "which crash looks bad" to "which fix produces the most impact per hour of engineering time."
Issue Categories, Workflow Integration, and Assignment (0:27 - 0:37)
Each issue in the list is categorized by impact level, frequency, and frustration contribution. From the same view, your team can assign the issue to the responsible squad, set ownership, and create a Jira ticket without leaving the dashboard.
This is the workflow integration layer. The prioritization is only useful if it connects to how your team actually operates. Creating a Jira ticket from a ranked, context-rich issue view is faster and more accurate than doing it from a raw crash report.
Drilling Into the Issue (0:37 - 0:42)
Clicking any issue in the list opens the full diagnostic view: affected sessions, device and OS breakdown, user journey context, network calls that preceded the crash, and the stability data for the version where the issue first appeared.
This is where the Mobile App Crash Analytics article and the prioritized list connect. Crash analytics tells you what happened and why. The prioritized list tells you which instance of "what happened" to investigate first.
The Outcome: Fixing What Actually Matters (0:42 - 0:53)
The video closes on the core argument: by focusing engineering effort on the highest-impact issues first, teams produce a measurable improvement in app quality per sprint, rather than a sprint's worth of work that moves the wrong metrics.
The Frustration-Free Session Rate: What It Is and Why It Matters
Frustration-free session rate is the percentage of app sessions that completed without a crash, an ANR, a UI hang, or a forced restart. It is a more complete measure of user experience than crash-free sessions alone, because it captures non-crash failures that users experience as friction without the app technically crashing.
The benchmark: Luciq's 2026 Mobile App Performance Playbook puts median crash-free sessions at 99.95% across enterprises. Frustration-free session rate compounds on this. A session can be crash-free but still frustrating if the user encountered a three-second UI hang before completing a transaction.
Teams that track only crash-free sessions are measuring a subset of user pain. Frustration-free session rate measures the full cost.
Using frustration-free session rate as the primary signal for crash prioritization means your issue ranking reflects the full user experience, not just the subset that resulted in a fatal error.
Mobile App Crash Prioritization and the Agentic Triage Advantage
In Agentic Workflows: The Blueprint for Mobile Engineering Leaders, Luciq SVP of Engineering Dalia Havens makes a specific argument about the maintenance trap: mobile teams lose 30 to 50 percent of engineering capacity to reactive maintenance not because the fixes are hard but because the investigation and triage process is slow and repetitive.
Impact-based crash prioritization directly addresses the triage half of that equation. If your team consistently starts with the right issue - the one that matters most, not the loudest one - the investigation time stays constant but the business impact of each resolved issue goes up.
The fix is the same amount of work. The ordering makes it worth more.
From Mobile App Crash Prioritization to Fix: The Full Loop
Mobile App Prioritization is the entry point. The loop closes when the fix ships.
Once the highest-impact issue is identified and assigned, the next step is root cause analysis, understanding why the crash is occurring, not just that it is. The Luciq Agentic Debugging article covers how the platform accelerates that step, using session context and crash data to surface root cause in seconds rather than hours.
After the fix is built, it goes back through the release pipeline, which brings the automated rollout rules and feature flag monitoring back into play. The cluster connects here: the issue list identifies the problem, the engineering workflow resolves it, and the release management layer ensures the fix ships safely.


