














TL;DR: Mobile application performance monitoring is the practice of capturing, analyzing, and acting on performance data from a live mobile app, including crashes, network failures, UI degradation, and user session behavior. Traditional APM tools were built for backend infrastructure and bolted onto mobile as an afterthought. Luciq, the first and leading Agentic Mobile Observability platform, offers a purpose-built approach to mobile application performance monitoring that closes the loop from detection to resolution without manual triage, context switching, or reproduction dead ends. This is what modern mobile application performance monitoring looks like in 2026.
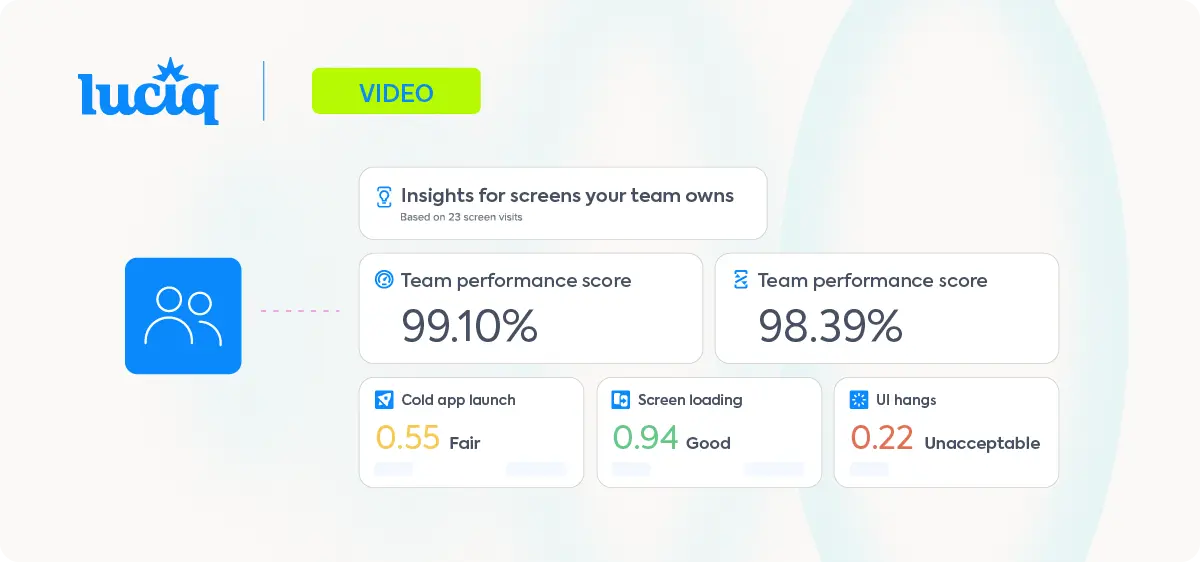
A mobile engineering lead at a scaled fintech pulls up the mobile application performance monitoring dashboard on a Monday morning and sees a clean green status. Uptime is good. API response times are within SLA. No alerts fired over the weekend. By Tuesday, the app has dropped from 4.6 to 4.3 stars on the Play Store, and the most recent reviews all mention the same complaint: the app "keeps failing" during a specific flow.
The dashboard is not wrong. It is just looking at the part of the stack that was not the problem. And for most mobile teams running backend-first mobile application performance monitoring tools, this is not a one-off incident. It is the week-in, week-out failure mode of trying to monitor a mobile app with infrastructure that was built for something else.
What Mobile Application Performance Monitoring Actually Means in 2026
Application performance monitoring, as defined by Google Cloud, is the practice of gathering and analyzing telemetry data to detect, diagnose, and resolve application performance issues before they impact end users. Mobile application performance monitoring applies that discipline to the specific reality of production mobile apps.
Mobile Changed the Mobile Application Performance Monitoring Equation Entirely
A mobile app does not run in a controlled server environment. It runs on thousands of device configurations, across dozens of OS versions, on networks ranging from fiber to barely-there 3G, in the hands of users who have zero tolerance for failure and a competing app one tap away. That is the environment mobile application performance monitoring is actually operating in.
The Signals That Matter in Mobile APM Look Nothing Like Server Metrics
The performance signals that matter in mobile application performance monitoring (crash frequency by device, API timeout rates by carrier, UI frame drops on specific screen sizes, session abandonment at specific journey points) are fundamentally different from what backend APM tools were designed to capture. Teams that try to force backend observability onto mobile application performance monitoring end up with incomplete data, opaque crash signals, and a triage process that consumes more engineering capacity than the fixes themselves.
The Mobile APM Market Is Growing for a Reason
Fortune Business Insights reports the global application performance monitoring market was valued at $9.85 billion in 2025 and is projected to reach $35.66 billion by 2034, at a 15.37% CAGR. The growth is not evenly distributed. The fastest-expanding segment is mobile-first, agentic APM, because that is where the gap between what legacy tools offer and what modern engineering teams actually need is widest.
The Four Layers of Mobile Application Performance Monitoring
Modern mobile application performance monitoring is not a single tool or a single metric. It is a workflow with four distinct layers, each addressing a different failure mode, and each requiring a different kind of visibility. When any one of them is missing, the signals from the other three become substantially less actionable. This is the structure mobile application performance monitoring has to take to matter in 2026.
Layer 1: Crash Detection and Resolution in Mobile APM
The most visible failure mode in mobile is a crash. But visibility into the crash event itself (the stack trace, the device, the OS version) is only the starting point. The layer most teams are missing is what comes after detection: automated root cause analysis across multiple crash occurrences, business-impact prioritization, and fix generation that does not require a developer to spend half a sprint in a reproduction loop. This is the part of mobile application performance monitoring agentic crash analytics was built to own.
Instead of alerting a developer that a crash happened, an agentic system identifies the pattern driving the crash across hundreds of occurrences, generates a code fix, and produces a ready-to-merge pull request. The four-to-eight hour triage cycle compresses into minutes.
▶ Watch | How Luciq Accelerate Crash Fixes
Deep dive | Mobile App Crash Analytics: From Detection to Merged Fix
Layer 2: Developer Workflow and IDE Integration
The second layer of mobile application performance monitoring is where the fix actually gets written, and where most mobile teams lose hours they do not account for. Investigating a production issue requires switching between the IDE, the observability dashboard, the session replay tool, the network log viewer, and back again. Every switch breaks flow state. Dr. Gloria Mark's UC Irvine foundational research shows it takes 23 minutes and 15 seconds to fully return to a task after an interruption. Every broken flow state adds meaningful time to resolution.
The Luciq MCP server eliminates that switching entirely. By bringing crash data, stack traces, pattern recognition, and user feedback directly into the IDE, developers can move from alert to fix without leaving their coding environment. For teams already working with AI-assisted development tools, it is the production observability context that makes those tools accurate rather than fast-but-uninformed. In mobile application performance monitoring terms, it is the layer that converts signal into resolution.
▶ Watch | The Luciq MCP Server in Action
Deep dive | CI/CD for Mobile: How the Luciq MCP Server Eliminates Context Switching
Layer 3: Bug Reporting and Quality Assurance
The third layer of mobile application performance monitoring is what happens when a user finds the issue before your monitoring does. In-app bug reporting is the production QA signal no test suite can replicate: real users, real devices, real network conditions.
A text description of a problem is noise. A bug report with an attached session replay, device data, OS version, network state, and automatic log capture is a resolution waiting to happen. When full context is attached to every user-filed report, the back-and-forth reproduction loop disappears. The developer opens the report and sees the exact failure point immediately. Triage becomes prioritization rather than investigation, which is what mobile application performance monitoring looks like when QA is part of the monitoring loop.
▶ Watch | Bug Report to Resolution with Luciq
Deep dive | Mobile App Quality Assurance: From Bug Report to Resolution
Layer 4: Network Observability in Mobile APM
The fourth layer is the one most mobile application performance monitoring stacks miss entirely. Crashes are visible. Network failures often are not. They produce a user who waited, got nothing, and left without filing a report or triggering a crash event. API timeouts, slow DNS resolution, server-side failures on specific carriers. These are the performance issues that show up in churn data and app store reviews long before they show up in a monitoring dashboard.
Network observability for mobile means capturing every API call within a session, categorizing failures by client-side vs. server-side origin, breaking successful-but-slow requests into granular lifecycle spans, and linking every network event directly to the session replay of the user who experienced it. The technical signal and the human impact become visible in the same workflow, which is the point at which mobile application performance monitoring starts paying off in retention rather than just alert volume.
▶ Watch | Network Observability with Luciq
Deep dive | Mobile App Performance Metrics: How Network Observability Protects Revenue
Why Mobile Application Performance Monitoring Requires a Purpose-Built Approach
Backend-first APM tools, Datadog, Dynatrace, New Relic, were not designed for the client-side context that mobile application performance monitoring requires. They capture what happens on the server. They do not capture what happens on the device: the specific gesture sequence that preceded a crash, the exact network condition that caused a timeout, the UI frame drop that made a transition feel broken even though no error was thrown.
Adapted Is Not the Same as Built For
Luciq is the first and leading Agentic Mobile Observability platform, purpose-built for mobile application performance monitoring from the ground up. Every layer of the stack described above (crash analytics, IDE integration, bug reporting, network observability) is designed around the reality of mobile production environments, not adapted from backend infrastructure tooling.
The Mobile APM Loop Closes Autonomously
The result is a mobile application performance monitoring workflow that closes the loop from detection to resolution autonomously, without manual triage at each step. That is what separates agentic mobile observability from traditional APM, and it is why engineering teams using Luciq report cutting maintenance workload by 30–50%.
Mobile APM and Real User Monitoring (RUM) Converge
Modern mobile application performance monitoring increasingly overlaps with real user monitoring. RUM captures what real users experience in production. Mobile APM captures what the app is doing under the hood. The leading mobile application performance monitoring platforms in 2026 do both in the same workflow, which is how engineering teams move from "the app is up" to "the user's experience is good."
See Luciq's full mobile application performance monitoring workflow in action → Book a demo.


